Deploying an App on OpenShift
Deploying an app to OpenShift is the easiest method I've used to get application code running in containers. I've spent hours writing Docker files and building YAML deployments for Kubernetes, and even more time troubleshooting ingress resources and overlooked dependencies. With OpenShift, I can check my code into GitHub and then point and click (or script) my way to a working deployment in just minutes. No need to write a dockerfile, no manual YAML writing, no developing interim build images or working with bespoke DevOps tooling. Just write code and then deploy it with one simple interface. This post covers deploying a classic three tier application (web app, API, database) using a Todo list application I developed with Svelte and dotnet core and a Microsoft SQL database running in a Linux container.
The Todo Application
First, a little about the app we'll be deploying. This is a very basic Todo list app that can add, update, and delete todo items from a list. Since this post is mostly focused on the simplicity of deploying an app on OpenShift, I tried to keep the application code as minimal and readable as possible. The frontend is written in Svelte, a Javascript framework known for it's speed and simplicity. This is my first attempt at a Svelte app, so be kind.
The Todo API is written in C#, and uses the excellent featherhttp framework from David Fowler. I used one of David's todo examples and added EF support for SQL server, some minimal CORS settings and a few additional methods.
I've chosen Microsoft SQL for the database backend just because I wanted to try SQL Server in a Linux container. An enterprise environment that has OpenShift probably also has MS SQL deployed somewhere and could benefit from migrating to containers so it seems like a good fit for this exercise. Ultimately the API is using Entity Framework Core, so it could easily connect to any other RDBMS or NoSQL provider and aside from just being curious about SQL on Linux I would probably have chosen MongoDB.
The code for both the web app and API is available in my GitHub todo repo.
Starting a project
I'll begin with a new project in OpenShift. As I've mentioned before, OpenShift is an Enterprise Distribution of Kubernetes much like RHEL is an Enterprise Distribution of Linux. OpenShift introduces some custom resources on top of vanilla Kubernetes, and the first one is a Kubernetes namespace with additional annotations. This resource is called a project.
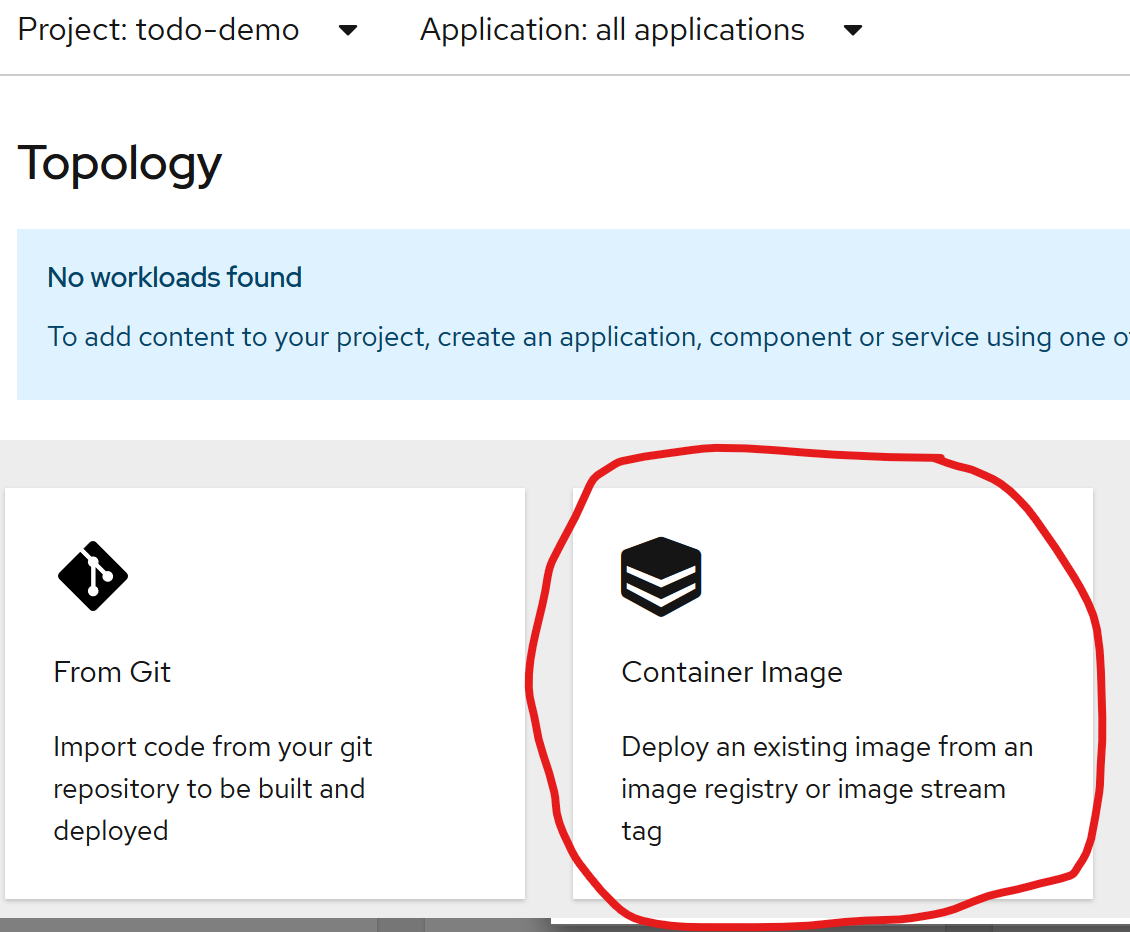
I created a project named todo-demo in the UI by clicking the drop down next to 'Projects', typing the name and clicking 'Create'

I'll also note the command-line equivalent of each step like so:
oc new-project todo-demo
Deploying the database
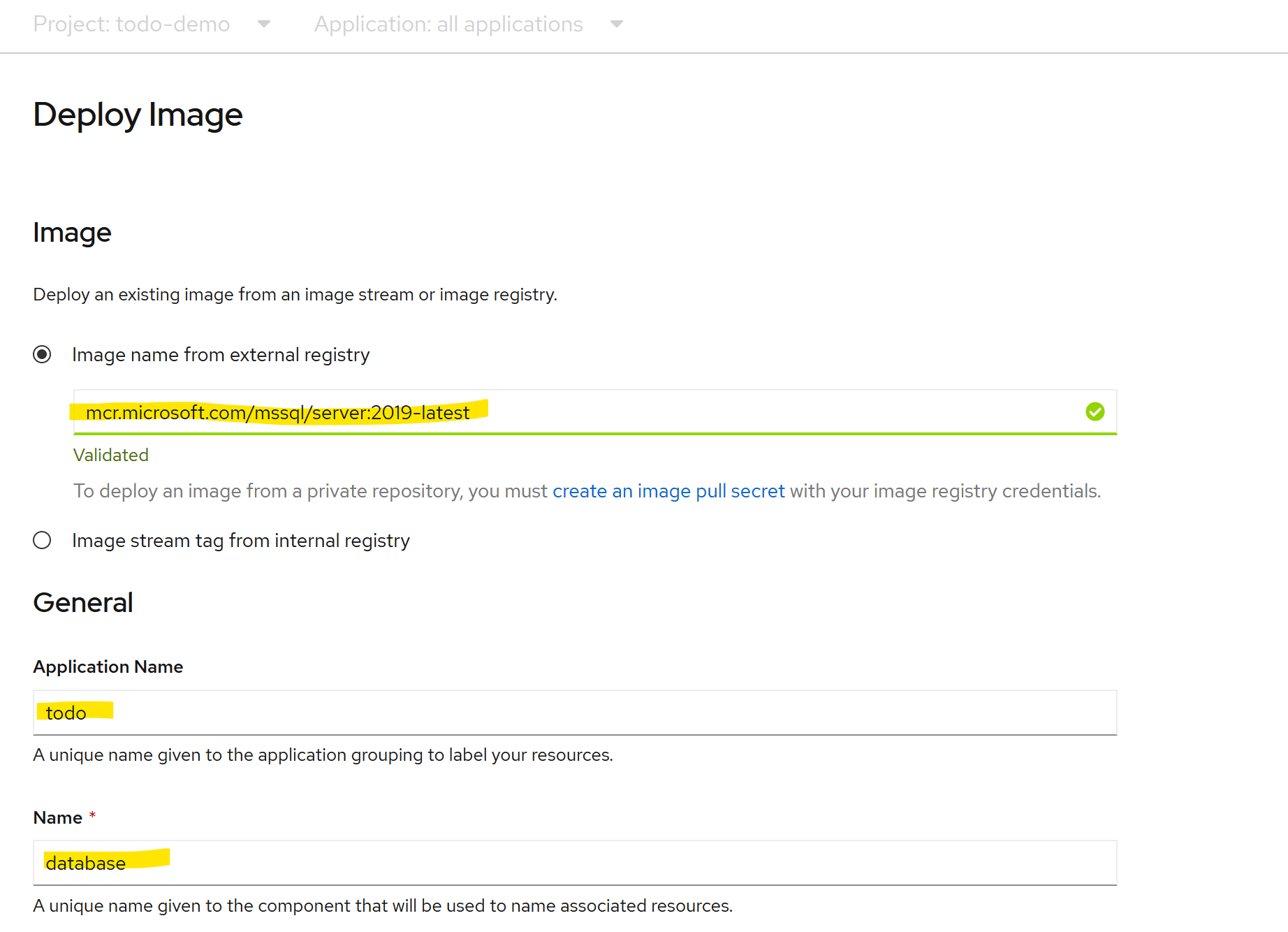
The first component I want to deploy in my new project is the database. I've chosen Microsoft SQL Server so I will create a deployment from the MSSQL container image, using the latest version of SQL 2019. This image requires two environment variables, "ACCEPT_EULA" (for accepting the SQL license terms) and "SA_PASSWORD" (for setting the password for the SQL sa login). I'll use the same application name for all components, "todo".
I named this component "database". This is important to remember as it is also the DNS name that SQL will be known by within the cluster, so later when connecting the API to this database I will use this name.
|
|
Note that I'm using a public Docker image from the Microsoft Container Registry, mcr.microsoft.com/mssql/server:2019-latest. You can browse available images and find required variables and usage instructions on Docker hub
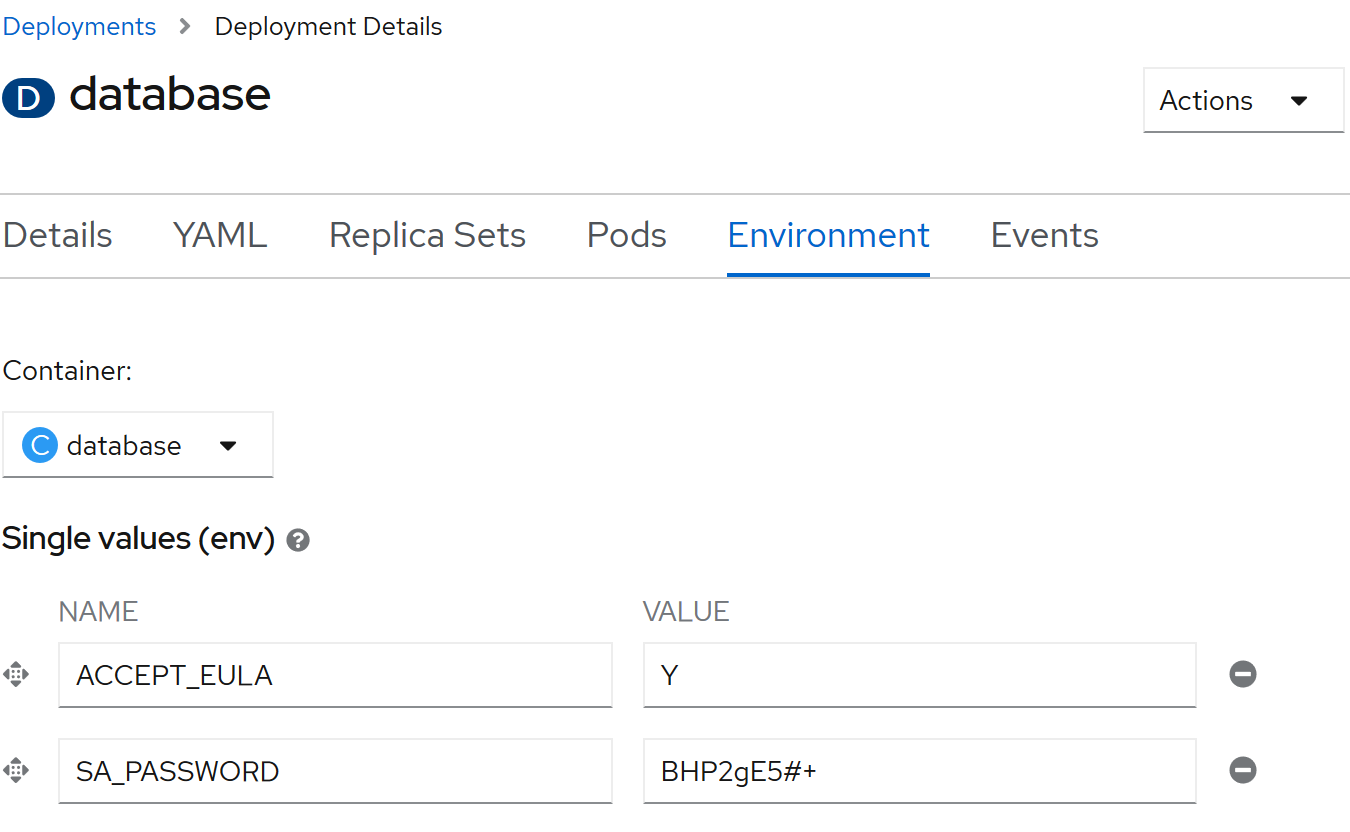
When creating the component in the web interface, it's deployed as soon as you click Create. This image requires two environment variables, which can be provided by editing the database deployment and setting the values as follows:

|
|
Conveniently, this can be accomplished in a single step by using the command-line:
oc new-app --docker-image=mcr.microsoft.com/mssql/server:2019-latest --name=database -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=BHP2gE5#+" -l app.kubernetes.io/part-of=todo
Now that the database is up and running, we can move on to deploying the API. That was BY FAR the easiest install of Microsoft SQL Server I've ever done.
Deploying the API
This is where it really gets exciting. I haven't created a dockerfile for the API, I've really just barely finished the code and pushed it to GitHub. Now, I'll tell OpenShift to deploy that code next to my SQL database.
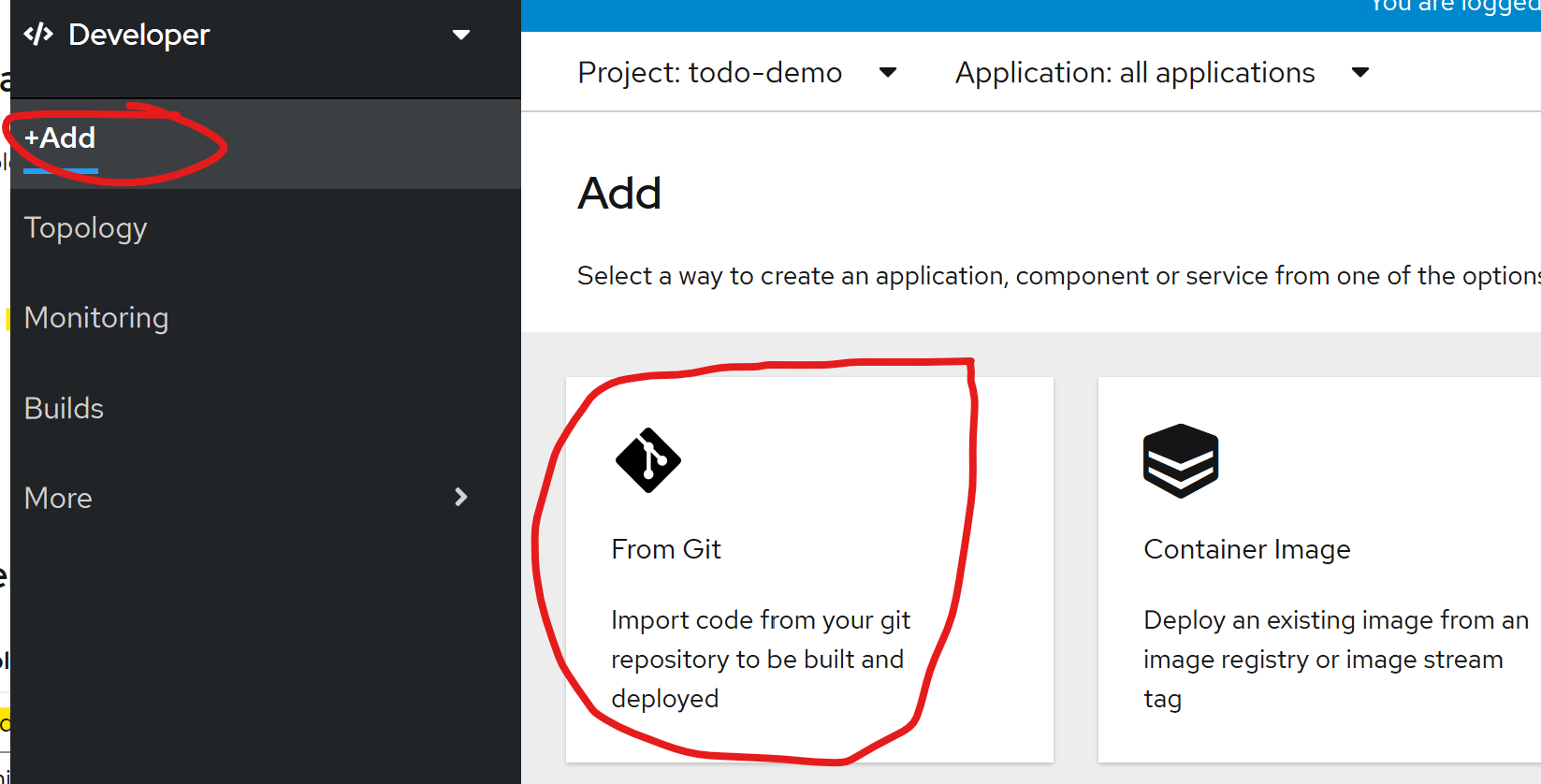
First, I'll click 'Add' and select the 'From Git' option. On the following screen I'll provide my Git repo URL, https://github.com/michaelburch/todo, and since I have both the web app and API in a single repo I will use advanced options to specify a path so that only the API is built.
|
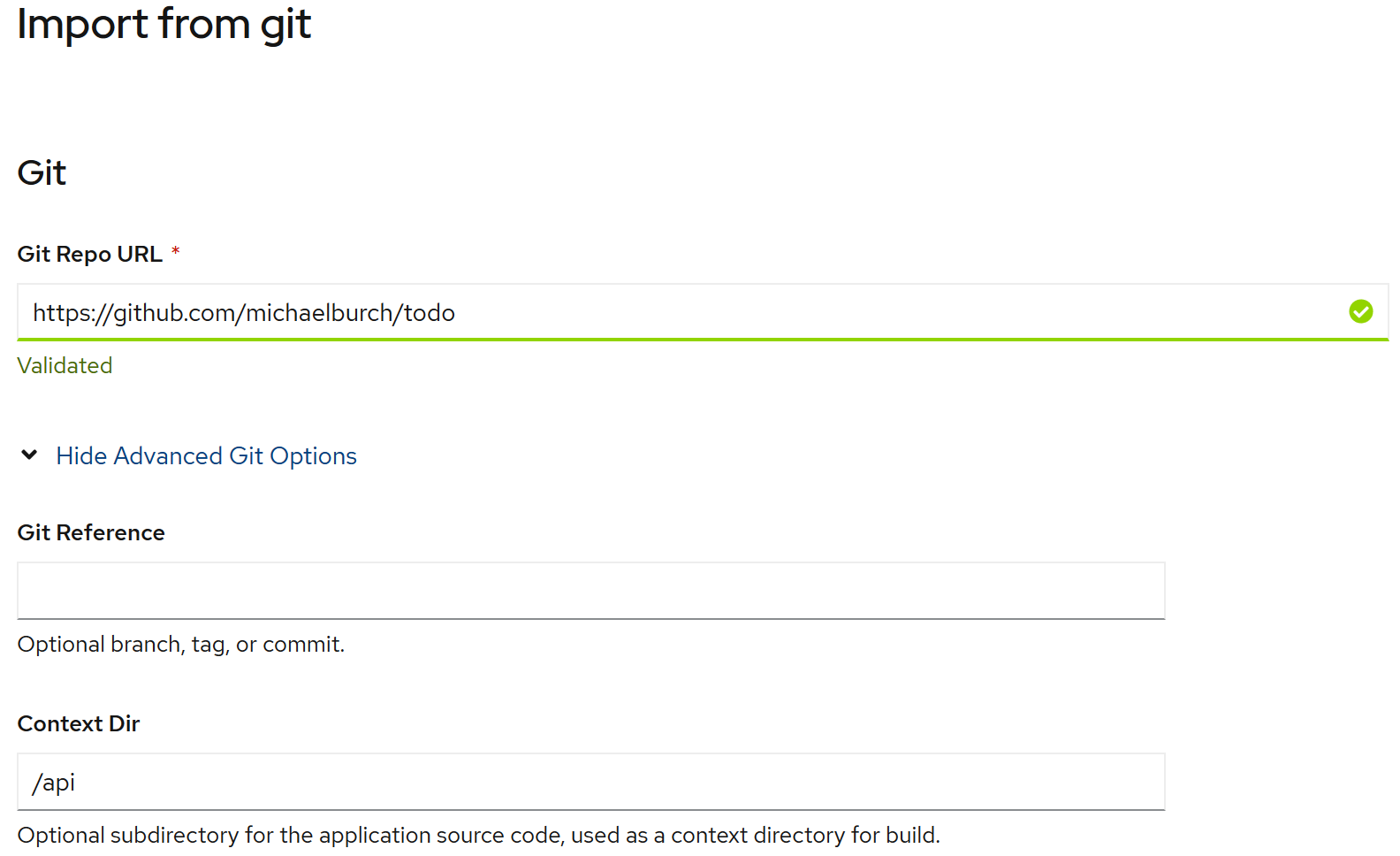
|
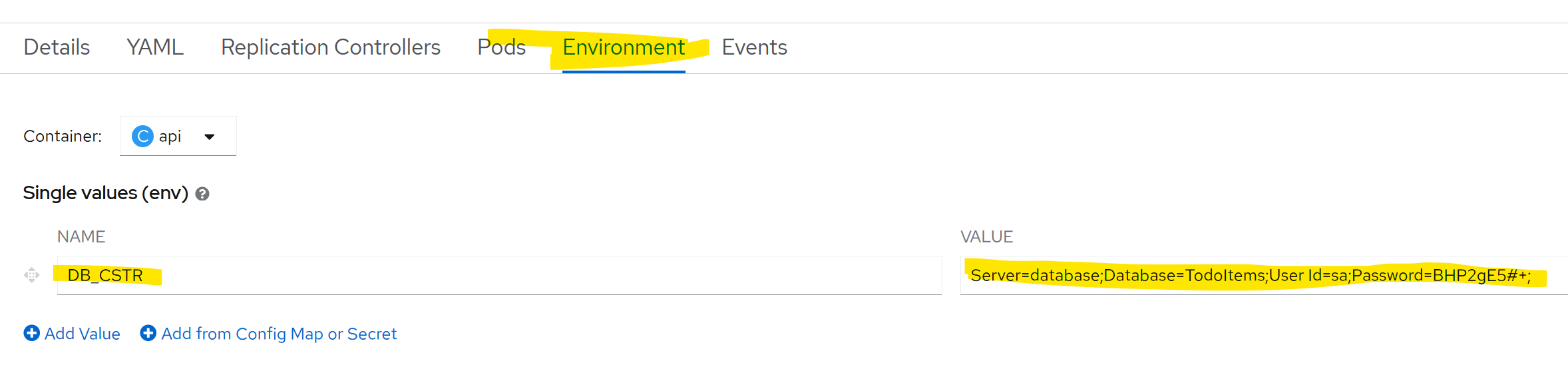
Next, I'll select a builder image, name my component and click create. OpenShift will then grab my application code, build a docker image, push it to an internal (to OpenShift) container registry and deploy the container for me! I want the API to connect to the SQL server I just deployed, so I will provide the connection string in an environment variable
DB_CSTR="Server=database;Database=TodoItems;User Id=sa;Password=BHP2gE5#+;"
The API itself is built on dotnet core, so I'll select the latest dotnet core builder image.
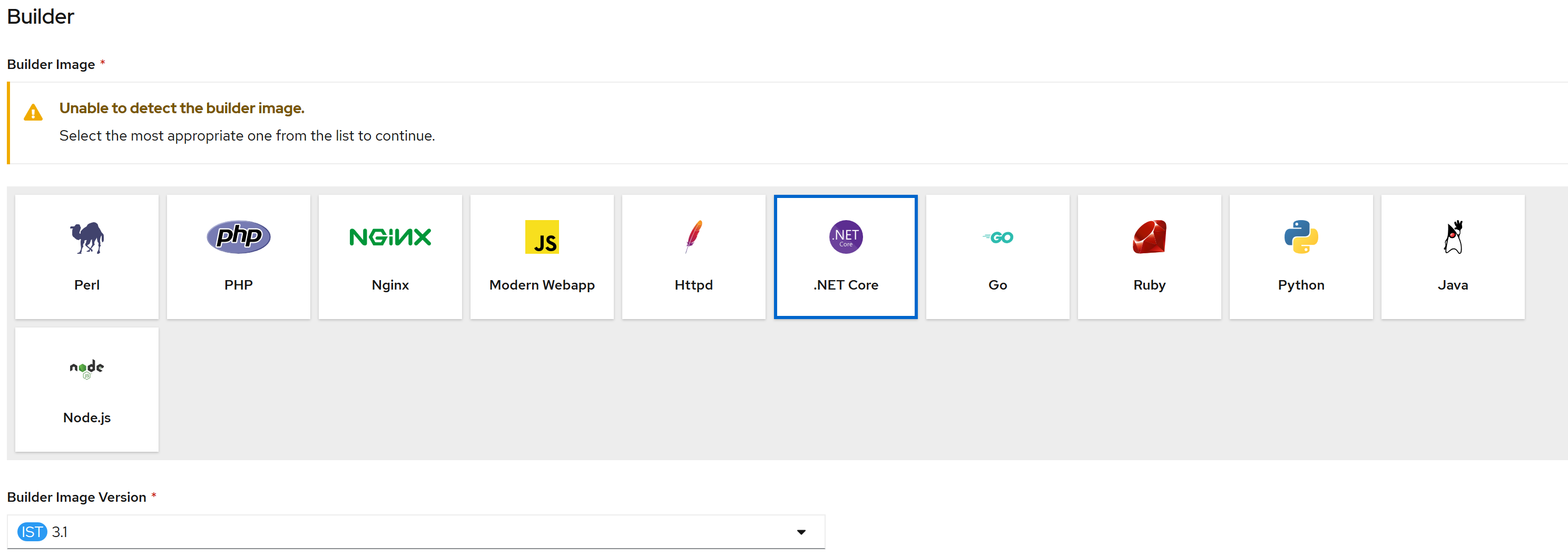
|
|
|
|
Again, the command-line saves a few steps. This time though, the API needs to be exposed (meaning accessible outside of the OpenShift cluster) so that when I load the app in my browser it can communicate with the API. The API is exposed with just one extra line:
oc new-app https://github.com/michaelburch/todo --context-dir=/api --name=api -e "DB_CSTR=Server=database;Database=TodoItems;User Id=sa;Password=BHP2gE5#+;" -l app.kubernetes.io/part-of=todo
oc expose service/api
I'll need to know the URL for the API before I deploy the app. I can see that through the topology view by clicking on my API component and looking at the route value:

or via this command:
oc get route/api
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
api api-todo-demo.apps-crc.testing api 8080-tcp None
This command shows the hostname I can use to access the API. The full URL, defined by routes in my API code will be http://api-todo-demo.apps-crc.testing/api. The API is using an Entity Framework 'code-first' database, so the database will be created on the first request if it doesn't already exist.
Deploying the app
Deploying the web app follows the same pattern as the API deployment. I used the same repo, specifying '/app' for the context folder this time and selected the NodeJS Builder image.
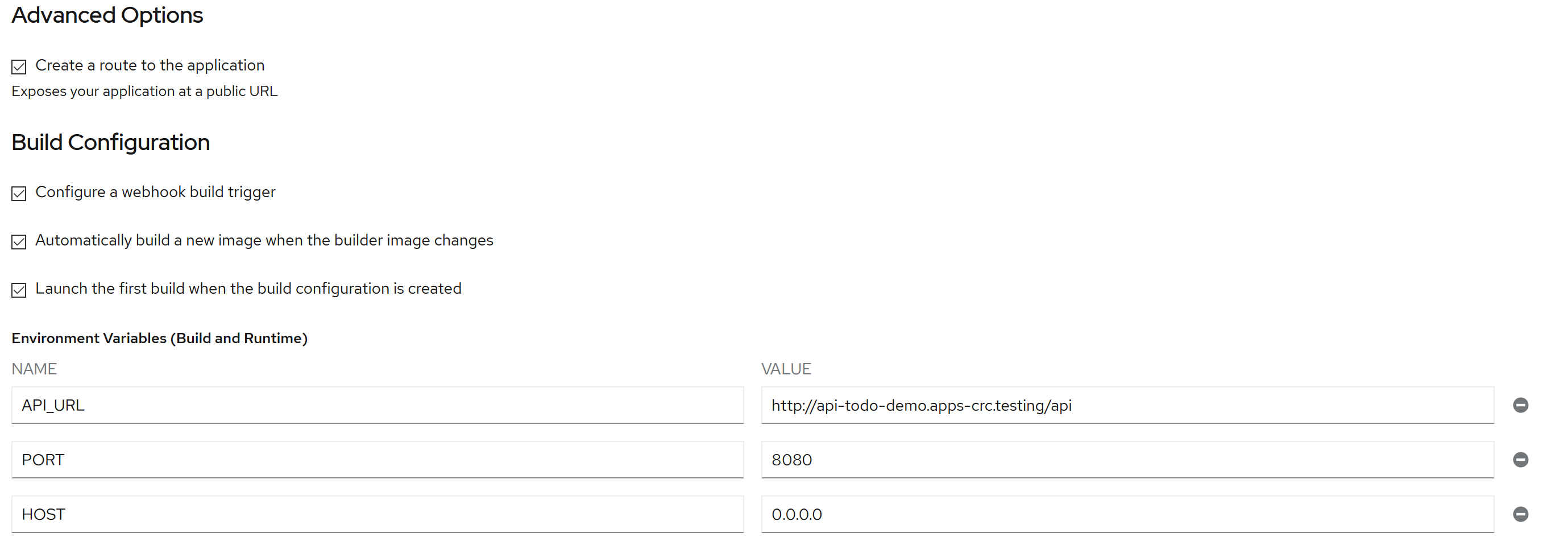
Since this is a Javascript app that runs in the browser, there is no 'environment' to pull variables from. This means that any configuration variables need to be passed to the app at build time. It's easy to provide these values when creating the component and specifying the build image:
|
|
I've set the API_URL to the route URL created in the previous step. I've also set some common Node build variables, HOST and PORT, to configure the app to listen on a default port and all IP addresses.
Clicking on the arrow next to the web app in the topology view will open the app in a new tab.
Too easy!
Despite having a less than awesome experience setting up my OpenShift development environment, I think this is where the product really shines. I was able to go from nothing to a fully deployed three tier application in under 10 minutes, which is even more impressive considering that one tier is Microsoft SQL Server.
I'm always suspicious when I hear that something complex (like Kubernetes) can be made simpler by adding another complex thing to it (OpenShift). In this case I think it's true. I originally set out to answer the question "Why bother with OpenShift?" and with this little test I think the answer is "because it shortens the time between writing code and having it up and running". I didn't want to like OpenShift, but I really enjoyed this and hope I'll get a chance to use it on a real project soon.
Just for fun
I like to verify that everything is really working as expected, so I exposed my SQL deployment with a NodePort service, fired up Azure Data Studio (AKA SSMS) and ran a simple query a few times while adding and updating items:

 Michael Burch is a technology professional and consultant focused on cloud modernization
Michael Burch is a technology professional and consultant focused on cloud modernization